

This scoping review evaluated the use of the term “digital twin” in healthcare, with a particular emphasis on HDTs. A secondary objective was to characterize the types of models labeled as “digital twins” across various organ systems and clinical applications, and to assess the extent to which these models adhered to the definition established by the NASEM. A total of 149 studies published between 2017 and 2024 met the inclusion criteria for this review. The results of the current study highlight a significant increase in research interest in digital twins in healthcare. This is supported by findings by Katsoulakis et al., who reported that publications regarding digital twins in healthcare have increased each year from 2017 to 2023, with a rising proportion of studies exploring such healthcare applications relative to the broader digital twin literature3. The expanded scholarship on HDTs coincides with the rise of related technologies such as IoT, AI, and advanced sensor systems, allowing for digital twin systems to become more easily accessible and feasible.
To provide context for the types of human models being developed, we established 13 retrospective system categories. Categories were determined based on the organ system or disease process primarily modeled. Studies evaluating cardiac models were the most common (n = 43, 28.86%), followed by metabolic models (n = 19, 12.75%), and musculoskeletal models (n = 18, 12.18%). Diabetic models accounted for over half of metabolic model publications (n = 13). Additionally, models focusing on the skeletal system alone predominated in the musculoskeletal model group (n = 13). In contrast, models of the epidermis, reproductive system, and surgical surface anatomy were infrequently represented, reflecting more limited HDT development in these domains.
The predominance of cardiac models underscores the research interest in precision cardiac care, mirroring its status as the number one cause of mortality worldwide158. The high clinical demand for cardiovascular disease tools, coupled with the relative feasibility of modeling cardiac perfusion and blood flow, helps account for the prevalence of cardiac models. Additionally, the heart’s function is relatively well-understood, and abundant, high-quality data from technologies like electrocardiograms (ECGs), MRI studies, and wearables make it a good candidate for modeling. The availability of quantifiable outcomes, such as heart rate and ejection fraction, allow for easier validation of models, driving their widespread development and adoption.
Similarly, metabolic digital twin models were likely widely developed due to the global prevalence of metabolic disorders like diabetes and obesity, which create a strong demand for personalized healthcare solutions. Like cardiac systems, these models have abundant data available, from biomarkers, lab tests, and wearable devices. These models hold significant potential for tailoring treatments by predicting individual responses to interventions such as medications, diet, and exercise.
The third most prevalent system modeled was the musculoskeletal system, for which most models were exclusively skeletal. This emphasis likely stems from the skeletal system’s foundational role in movement and load distribution, making it a logical starting point for biomechanical modeling. Moreover, bone structures are relatively straightforward to image and quantify using advanced modalities such as CT and MRI, facilitating accurate virtual reconstruction. Once imaged, bones can be modeled as mechanical structures with comparative ease, supporting the development of detailed and reliable simulations.
Interestingly, among the HDT models reviewed, no musculoskeletal models met the NASEM criteria for digital twins, and only a single cardiac model qualified. In contrast, eight of the 18 qualifying models (44.4%) were metabolic. Much of this can be attributed to the fact that only three unique metabolic models were identified across eight different studies. Metabolic models made up a disproportionately large share of NASEM-compliant digital twins—representing a threefold increase in relative representation compared to their ranking among all models included in the review. This overrepresentation of metabolic models among NASEM-compliant HDTs likely reflects both practical and conceptual factors. In many physiological systems, it is either difficult or unnecessary for the digital twin to directly influence its physical counterpart. The only fully autonomous HDT identified in this review was a cardiac model that modified the physical twin through automated defibrillator output. Outside of such specialized use cases, real-time updates to cardiac or musculoskeletal systems are more challenging to implement. For instance, while influencing heart rate may seem feasible in theory, implementing real-time adjustments to cardiovascular function typically requires indirect interventions and is less straightforward than metabolic modifications. A similar situation is realized when it comes to the musculoskeletal system, where an “update” to the physical twin conjures imagery of a robotic exoskeleton repositioning the patients’ limbs. On the other hand, updates to the metabolic system are easily realized in the form of recommendations regarding diet and exercise. Moreover, wearable devices such as continuous glucose monitors are comfortable, widely available, and capable of generating high-frequency data. By comparison, cardiac monitoring often relies on bulkier, less accessible tools (e.g. multi-lead ECGs or blood pressure cuffs), which may limit their integration into real-world, continuously updated HDT systems. Other organ systems, such as neurological or reproductive systems, are less represented likely due to lesser demand (relative to cardiac, metabolic, and musculoskeletal systems) and the reduced availability of high-quality data for model training and validation. Additionally, monitoring of these systems tends to be less straightforward than cardiac or metabolic systems. The technology required to perform such data collection, particularly in a continuous manner, may not be commonly available relative to devices such as wearable fitness trackers, portable blood pressure cuffs, or glucose monitors.
However, several emerging technologies may help address these limitations and expand the applicability of HDTs across a broader range of medical domains. In neurology, the growing adoption of wearable EEG headsets, brain-computer interface devices, and smart neurostimulation implants may soon enable continuous monitoring of brain activity in real-world environments. This could facilitate the development of digital twins for epilepsy management, neurodegenerative disease tracking, and cognitive function modeling. In reproductive health, advances in transdermal hormone sensors, smart fertility trackers, and implantable pelvic monitors could allow for dynamic modeling of ovulatory cycles, hormone fluctuations, and pelvic floor disorders. Beyond sensor hardware, advances in AI, particularly in multimodal data fusion and time-series forecasting, may allow researchers to synthesize heterogeneous data sources such as patient-reported outcomes, clinical notes, imaging studies, and wearable sensor data into cohesive, patient-specific digital models. This would decrease the amount of sensor data needed, placing more of an emphasis on dynamically updated patient history. Together, these innovations suggest that the delay in modeling of less common HDT systems may be temporary. As emerging technologies mature and become more widely accessible, it is likely that future HDT research will achieve broader system coverage, higher model fidelity, and greater clinical integration.
Despite the promise of HDTs to provide precision healthcare, the current study reveals several challenges to their development and classification. As per the inclusion criteria, all evaluated papers referred to the model at the center of their study as a digital twin. However, only a subset of these models met the definitional criteria outlined by the NASEM (Table 3). The factors necessary for compliance with the NASEM definition for digital twins are threefold. First, the system must be anchored by a mathematical model that represents the structure, behavior or function of a real-world object—in this context, the human body or one of its subsystems. Second, this mathematical model must be dynamically updated to reflect the evolving real-world circumstances of the physical object. In the present context, the model must be updated to reflect measured changes to the human body or one of its subsystems. Third, the model must possess predictive capabilities that inform the behavior or trajectory of the physical twin, ideally, to support goal-directed interventions or clinical decision-making. By our metrics, there was a single study12 that met the NASEM definition of a HDT in the traditional (i.e., engineering) sense, with the digital twin making automatic updates to the physical system to guide outcomes without external human input. Such systems are understandably rare, just as the conditions that warrant granting a device the unrestricted ability to effect physiological change to one’s body are rare. However, one such cardiac system was proposed by Lai et al.12. In their description, an implantable cardioverter defibrillator (ICD) would model a patient’s heart while monitoring for arrhythmias and restore normal function without human intervention. ICDs can provide timely therapies upon detection of irregular cardiac activity, but each individual patient requires personalized parameterization for these devices based on their personal cardiac history and device characteristics12. Furthermore, evolving conditions within singular patients necessitate that such parameters be adjusted regularly, though sometimes the need for such an adjustment can arise suddenly. The system proposed in Lai et al. would leverage ECG data to learn the patterns of a patient’s normal cardiac function and use this modeling as the basis upon which a digital twin of the patient’s heart was constructed. The digital twin monitored electrogram readings to detect arhythmic conditions. Upon discovery, it computes an appropriate electrical therapy to correct the cardiac dysfunction and then automatically administers the corrective action to restore the heart’s normal rhythm.
The other category that would meet the NASEM standard of a true digital twin would be human-in-the-loop type twins, of which there were 17 studies13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29. Like the automatic twin systems, these systems generate recommendations to direct a patient’s health trajectory toward a particular goal. However, in these systems, a human—usually the patient or their physician—decides whether or not to follow these recommendations and may make modifications to the prescribed action as they see fit. An example of such a system was documented by Bahrami et al., whose reports described a digital twin that simulated oral and transdermal uptake of fentanyl based on a patient-specific parameterization of their computational model14,22,24. Real-world measurements reported by the physical twin included the patient’s respiration rate and self-reported pain score, which were used to update the digital counterpart. By targeting a fentanyl concentration range in the patient’s plasma, an acceptable breathing rate, and a minimal discomfort level, the digital twin could advise dosing schedules and delivery methods (e.g., when to change patches) for an optimized fentanyl administration strategy.
A second example of a human-in-the-loop style HDT was Twin Health’s twin precision nutrition/treatment program18,26,27,29. Traditional dietary guidelines for managing type 2 diabetes (T2D) are often based on population-level data and may not account for individual variation in metabolic responses. The digital model was constructed using a range of clinical parameters and continuously updated with data from multiple IoT-enabled devices. These included wearable fitness trackers (capturing steps, heart rate, sleep, and physical activity), a smart scale, an arm-based blood pressure monitor, a continuous glucose monitor, and a smartphone app used by patients to log their meals. The system then provided nutrition and lifestyle recommendations in tandem with registered dieticians working as health coaches to aid in the implementation of such recommendations.
While models like the Twin Precision system exemplify digital twins that offer real-time, personalized feedback to influence patient behavior, not all virtual representations of humans function in this way. Some instead are passive models, lacking interactivity or bidirectional influence—characteristics more aligned with digital shadows. The present study identified 14 such examples30,31,32,33,34,35,36,37,38,39,40,41,42,43. Like digital twins, digital shadows are parameterized models that receive input from the physical twin, which dictates the trajectory of the model—the main difference being that digital shadows do not make recommendations or updates to the physical system. Digital shadows comprise a virtual reflection of a system or object in the real world or, in the context of this report, a virtual reflection of a human body or subsystem. For example, a 2023 paper by Ou et al. described a system enabling the creation of a digital shadow of a patient which could be utilized in medical applications37. Their model used a photo to generate a model of the user’s face. Then, through the use of a camera and various tracking sensors, the system rendered a realistic, real-time representation of the user’s body in a virtual space. The rendering included simultaneous digital depictions of whole-body movements, facial expressions, and gaze direction. By faithfully conveying a patient’s posture and mental status, the team posited that the live avatar could constitute a virtual stand-in for telemedical applications or serve as a venue for life coaching systems for children with autism (potentially reducing social barriers in virtual peer interactions).
In contrast to digital shadows, which serve solely as passive reflections, personalized digital models are designed to simulate individualized physiology without requiring real-time updates. The present study identified 87 models fitting this category6,7,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127,128. Personalized digital models share the individual customization of the digital shadows and the digital twins, but their parameters are not continuously updated by data from the physical twin. In some cases, these models are used to assess the current state of a patient and make a recommendation. In other cases, the model is created simply as a proof-of-concept or to gain an understanding of some aspect of the physical twin that is not easily observed using traditional instruments.
For example, a patient with a complex medical condition may face several possible treatment options. In such scenarios, a personalized computer model can be used to simulate each intervention and predict the likely outcome. Assuming the simulations are accurate, the physician and patient can select an appropriate therapy based on the predicted results. In these cases, once a successful intervention has been selected, further simulation is no longer required. The current study has identified 31 such models7,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73. A study by O’Hara et al. exemplified personalized models offering one-time decision support55. In this system, a digital clone of a patient’s heart was generated from cardiac magnetic resonance data. The digital model was then used to predict abnormal electrical pathways in the patient’s heart that were causing irregular heartbeat rhythms (ventricular tachycardia circuits) for treatment via radio frequency ablation (RFA), a procedure that targets and destroys abnormal tissue to restore normal heart function. Once a successful ablation had been administered, there was no further need for the model and simulations were discontinued.
Beyond decision-support applications, many personalized digital models were developed for research, proof-of-concept, or physiological modeling purposes without directly informing clinical care. The present study identified 56 personalized models that did not inform treatment decisions6,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127,128. An example of one such report is illustrated by Gillette et al.76. This study was a proof-of-concept demonstrating that a heart model suitable for use in a biophysically accurate HDT could be generated in a largely automatic fashion in a time frame deemed useable in a clinical setting. Using data from an MRI scan and a clinical, 12-lead ECG, their model captured the three-dimensional geometry of the heart, as well as a parameter vector specifying a comprehensive list of factors describing electrical processes which govern contraction of the lower heart chambers (ie ventricular activation and repolarization sequences). This model was not used to detect disease or inform a treatment strategy, though, in the future, it could be theoretically capable of synthesizing high fidelity ECG signals with near real time performance.
Cardiac models were represented in all types of models examined but were particularly prevalent as personalized digital models that were not used for decision support (n = 24). Oftentimes, these models aimed to mirror the cardiac physiology for a particular patient without providing output or recommendations. Either of the recently referenced examples of personalized digital models might constitute the foundation for a HDT if efforts were made to continually update each model with a parameter set reflective of the evolving conditions specific to the patient each model describes. Such is the case with most (if not all) of the models that have been presently categorized as personal models (cardiac or otherwise), though many of the situations reported upon did not require a full digital twin to achieve successful outcomes. Furthermore, many studies acknowledged that their model only constituted a digital twin insofar as their work represented a piece for inclusion within a larger digital twin project, whereby they contributed their piece to the digital twin puzzle.
While many personalized models are built around individual-level data, others lack this degree of specificity and are instead designed to represent average or theoretical human physiology. This study identified 15 examples of “digital twins” that are better described as general digital models129,130,131,132,133,134,135,136,137,138,139,140,141,142,143. Like the other systems detailed previously, general digital models are mathematical representations of—in our current context—humans or human subsystems. However, these model types are not specific to a particular individual. General digital models often predict outcomes that are statistically likely for a given population, but which will often diverge from the disease progression experienced by a particular individual. For example, the virtual liver model in Dichamp et al. contributed to the general understanding of liver processes, but did not aim to predict liver function in any specific individual139. In this paper, a mechanistic description of acetaminophen (APAP) hepatoxicity was presented which has allowed researchers to make reasonable extrapolations of APAP detoxification from laboratory measurements.
Some studies focused on creating simulated populations rather than representations of individual patients. These virtual patient cohorts serve as another distinct modeling approach commonly but inaccurately labeled as digital twins. The current study identified 15 examples of virtual patient cohorts8,144,145,146,147,148,149,150,151,152,153,154,155,156,157. A virtual patient cohort is a simulated group of patients generated via computational models and data to study disease patterns, treatment outcomes, or other medical scenarios without involving actual individuals. This approach allows researchers to explore and analyze various medical conditions and interventions in a controlled, virtual environment, often in-lieu-of or preliminary-to traditional clinical studies. For example, in a 2024 report Joslyn et al. described a 10-patient virtual cohort that was parameterized to reproduce experimental cellular kinetics observed in real patients151. The digital patients were then treated with different types of T cell therapies, and the analysis helped elucidate the biological processes governing such therapies in the body.
Beyond model classification, an important theme that permeates the NASEM report on digital twins is the assertion that the digital representations should be fit for purpose. The report stated that the technical details of the virtual representation—model types, fidelity, resolution, parameterization, and quantities of interest—must be selected to align with the specific decision task and computational constraints. While early conceptualizations of digital twins often emphasized high-fidelity, physics-based simulations, current thinking is more pragmatic: what matters most is that the model fulfills its intended purpose, regardless of its underlying structure. The models included in the present study featured a wide range of complexity, from rules-based systems to mechanistic models simulating the underlying physics. The distribution of model types showed a slight preference for empirical approaches (42.95%), followed by mechanistic (31.55%) and hybrid (25.50%) models. While empirical models were somewhat overrepresented, the overall balance among the three categories remained relatively even. Among the models meeting the NASEM criteria for digital twins, the distribution shifted further in favor of empirical approaches. These comprised the majority (61.11%), followed by mechanistic (22.22%) and hybrid models (16.67%). In this category, a disproportionately large number of the studies consisted of multiple reports on what is probably the same model. When considering a count of likely unique models, empirical models comprised 66.66%, with hybrid and mechanistic models splitting the remainder (16.67% each).
In addition to the complexity and fidelity of the models, the sensors used to inform their digital counterparts similarly varied. Across the full set of included studies, 23.5% of studies used consumer grade sensors. However, when the focus was narrowed to only the digital twins meeting the NASEM criteria, the portion that used consumer grade sensors increased to 55.6%. Conversely, in the total population of included studies, the portion that employed clinical grade sensors was 61.07%, while the portion in the NASEM digital twin group decreased to 27.8%. This trend remained consistent even after adjusting for likely unique models. In that context, the proportion of consumer-grade sensors rose from 21.9% to 50.0% when shifting from the broader population to NASEM-compliant models, while clinical-grade sensor use decreased from 62.8% to 41.7%. This may reflect the need for portable sensors for the regular updates required by HDTs, whereas clinical sensors may be too large, expensive, cumbersome, and/or impractical for subjects to carry and maintain. This could be indicative of an outsized role that consumer grade devices may play in the evolving HDT research space.
In addition to model design and data input considerations, the rigor with which digital twin models are evaluated is critically important. In their report on digital twins, NASEM stressed the importance of verification, validation, and uncertainty quantification (VVUQ) for all aspects of digital twin research. In summary, verification involves checking that a computer program correctly implements and solves the equations of a mathematical model, including code verification and solution verification. That is, verification exists to ensure the computer programming correctly performs intended algorithms while assessing the accuracy of its solutions. Validation is about evaluating how accurately a model represents the real world with respect to its intended usage. Uncertainty quantification focuses on measuring incertitude in model calculations, with an aim to account for all sources of uncertainty and quantify the impact of each on the overall results. The nature of HDTs does not render researchers exempt from VVUQ considerations: the NASEM report specifically lists a cancer patient twin as an example scenario for which VVUQ protocols should be applied. In the present work, only two papers of all included studies contained the term VVUQ (in the body of the text). While both of these works conducted their studies in the spirit of VVUQ, they both pointed to reasons why a rigorous treatment of VVUQ standards cannot be satisfactorily applied at present. One64 highlighted the absence of a clear pathway for VVUQ in the context of obtaining regulatory approval for in silico clinical trials and digital patients. Roughly two thirds of included studies had some treatment of uncertainty and/or model validation, but a small subset of these addressed many of the VVUQ concerns without explicitly mentioning the term (e.g., refs. 57,88,94,126,128).
The importance of VVUQ in digital twin development cannot be overstated, particularly in healthcare, where model accuracy directly impacts clinical decision-making. For researchers wishing to employ a rigorous treatment of VVUQ, the American Society of Mechanical Engineers (ASME) Validation and Verification (V&V) Standards Committee in Computational Modeling and Simulation has released a suite of standards that can be adopted or serve as examples for HDT endeavors159,160,161. Additionally, the 2012 NRC report on VVUQ provides comprehensive guidance for those wishing to incorporate such practices into their work11.
Teams working on patient specific models for medical applications are already leveraging VVUQ methodology, and they can provide valuable insights into how VVUQ can be systematically assimilated into HDT research. For instance, Galappaththige et al. outline a comprehensive roadmap for incorporating VVUQ practices into the development of personalized digital models162. This team instructively demonstrates adherence to the ASME V&V 40 (2018) standards, which provide a robust framework for assessing model credibility in medical device applications. Similarly, the work of Santiago et al.163 and Nagaraja et al.164 showcase detailed strategies toward the design and execution of robust VVUQ plans, exemplifying how standardized methodologies can enhance model reliability and stakeholder confidence. Building on these examples, HDT researchers can develop these practices by leveraging established standards to define specialized VVUQ tailored to HDT applications.
The implementation of VVUQ in HDT studies will necessarily vary based on the model’s purpose, design, and clinical context. Mechanistic HDTs, which rely on physics- and math-based representations of human systems, require rigorous verification and validation to ensure that their theoretical frameworks are both accurate and adaptable to individual patients. These models must be customized to capture patient-specific parameters and reliably predict how different interventions will influence physiological outcomes. In contrast, empirically trained HDTs, often powered by machine learning, must focus on the adequacy and representativeness of their training data. These models require robust validation on external datasets and careful uncertainty quantification to ensure that their predictions generalize accurately to the human systems they aim to model. The degree of VVUQ stringency required also depends on whether the HDT outputs are interpreted by a human or implemented automatically. Human-in-the-loop systems can tolerate a higher degree of uncertainty because human judgment provides an additional safety layer. Conversely, HDTs that autonomously update the physical twin, such as implantable devices that adjust physiological parameters in real time, must meet far more stringent VVUQ standards to ensure patient safety. In these settings, model outputs are acted upon without human oversight, necessitating high confidence in model reliability and robustness. For instance, metabolic HDTs that provide lifestyle recommendations may tolerate some level of predictive uncertainty, as their outputs pose relatively low immediate risk. In contrast, cardiac HDTs that influence real-time hemodynamic parameters demand significantly lower uncertainty thresholds to prevent harm. Thus, the level of trust required, and the methods used to establish that trust must be tailored to the clinical application and technical design of the HDT.
Despite offering a comprehensive overview of the HDT landscape, this review is subject to several limitations that warrant consideration. While the categories discussed in this review are well-defined, the boundaries between categories can be unclear. This imprecision leads to a degree of subjectivity in categorizing and classifying the models and concepts reviewed. The subjective nature of these categorizations may influence the consistency and comparability of the results. Additionally, the categorization of models was retrospective and determined by the discretion of the authors to best summarize the body of publications regarding HDTs. To the authors’ knowledge, there are no well-established categorization systems for HDTs. As such, some studies may have fit into multiple categories with regard to model type but were placed into the one single category which was considered to be the best fit.
Additionally, this review is limited by the quality of the included studies. Concerns about study quality often center around methodological rigor and the validity of treatment outcomes. Since the present review is focused on the usage and interpretation of specific terminology, as opposed to the evaluation of medical interventions, the impact of study quality is somewhat diminished. Although variations in reporting standards and analytical approaches exist, these issues are less likely to skew the findings in the context of our analysis. Our primary concern is an assessment of how the term “digital twin” is defined and used across different studies, which, while important, does not carry the same weight as methodological issues would in a clinical review. Therefore, while the quality of studies remains a consideration, its relative impact on our conclusions is minimal compared to that in traditional systematic reviews. Furthermore, this team is unequipped to evaluate the general language competency of each group in a way that would be relevant to the present research, and any assessment we could perform would be highly subjective and of questionable value. Indeed, many of the typical measures of quality (e.g., bias, validity, sample size, study design, data collection methods) are all irrelevant to the context surrounding how each group used the term “digital twin”, so the measures of quality that should be employed in the present case are uncertain. In light of these considerations, the choice was made to not include a formal quality assessment.
Despite a lack of formal quality assessment, we observed that most studies successfully achieved their stated objectives—often focusing on evaluating model performance, even if the models themselves did not qualify as HDTs. However, methodological rigor varied considerably across the literature. Some studies demonstrated strong practices, such as incorporating real-world patient data, integrating multimodal sources, and clearly articulating their modeling rationale. Mechanistic studies often excelled at generating generalized models grounded in first principles. However, these models were typically the farthest from meeting the criteria for digital twins, as they lacked personalization or dynamic interaction with a physical counterpart. Empirical studies, on the other hand, were often methodologically sound in their approach to model development and evaluation—frequently dividing their data into training and testing sets and, in some cases, providing access to source code or datasets to support reproducibility. Despite these strengths, many studies lacked external validation, detailed reporting on reproducibility measures, or comprehensive approaches to uncertainty analysis. Empirical models were typically validated using held-out portions of the training data, while mechanistic studies were often limited to proof-of-concept demonstrations. More robust mechanistic models tested their predictions against real-world data, though such efforts were less common. This variation highlights the evolving nature of HDT research and reinforces the need for more standardized reporting, validation frameworks, and methodological transparency.
While variability in methodological rigor was evident, the findings of this review offer important insight into current usage patterns and definitional inconsistencies in the HDT literature. In our scoping review of publications including the term “digital twin” since 2017, we found that 18 out of 149 studies (12.1%) appropriately used the term in describing their models, while the remainder (87.9%) applied the term to models that did not align with the NASEM definition of a digital twin. Pervasive misuse of the term “human digital twin” confuses and complicates future efforts to advance healthcare.
Establishing a solid foundation for the term “human digital twin” requires setting clear standards for its usage. In order to effectively implement this concept, the health research community must embrace the framework set forth by the NASEM digital twin report. Going forward, the computational models appearing in HDT studies should incorporate three essential elements:
(1) a digital model parameterized to be representative of a specific individual.
(2) dynamic, ongoing updates to the digital twin model with data collected by sensors (etc.) reporting measurements quantifying the state of the specific individual (or part thereof) that the digital twin model represents.
(3) ongoing modification to the state or behavior of said specific individual, based on insights and predictions generated by the digital twin model.
Models which do not meet the definition of a HDT, such as digital shadows, general digital models, and virtual patient cohorts, should be categorized correctly and consistently in literature as well (Figs. 2 and 3).

Digital model is an all-encompassing term under which most, if not all, computerized models can be categorized. When a digital model is tailored to reflect the unique circumstances pertaining to a specific individual, they become personalized digital models. If a personalized digital model continually accepts input from the individual and updates itself accordingly, then the model can be considered a digital shadow. Digital shadows, however, are passive and do not alter the state or trajectory of the individual being modeled, merely providing a digital reflection of the individual. On the other hand, if a model that would otherwise be categorized as a digital shadow provides some form of predictive output that automatically makes decisions that affect the individual, or if it provides information that said individual (or their care team) uses to inform decisions affecting the individual (e.g. which treatment option to take, or how vigorously to exercise), then the model can be considered a human digital twin. Many of the personalized digital models examined herein were used to inform a single decision or treatment option for the individual, so the present study makes the distinction between personalized models that were used once for clinical decision support (CDS) and those that were never used to alter the individual’s trajectory. For a “used-once” personalized model to be considered a human digital twin, it would require that the model be updated after each decision was executed in order to inform additional decisions, in a continual, ongoing process. The personalized digital models that were not used for CDS are like digital shadows, except they only capture one moment in time, whereas the digital shadow will dynamically reflect the individual’s state in an ongoing process.
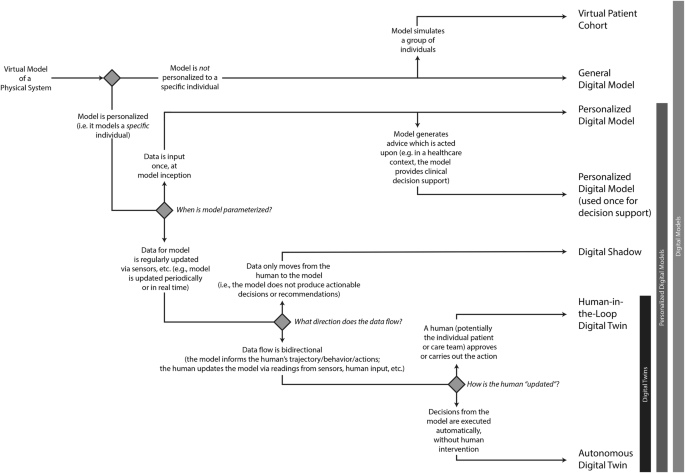
This flow chart can be used to determine the categorization of digital models, differentiating between virtual patient cohorts, general digital models, personalized digital models, digital shadows and human digital twins.
This comprehensive approach will ensure that usage of the term “human digital twin” is both consistent and accurate, setting a precedent for its future development and application in healthcare. This work provides a framework to systematically and rigorously categorize studies involving digital models and HDTs in healthcare, ensuring a more precise alignment with their conceptual definitions and promoting consistency in their scholarly classification (Figs. 3 and 4).

Data flows into a virtual model from a variety of sources, stemming from human subjects or their environment. Some models are parameterized exactly once, while others are dynamically updated in a recurring fashion. In digital twin models, the data flows from the model back into the data-sources (i.e. the subject or physical system is somehow modified based on predictions made by the digital twin) such that the ongoing model parameterization reflects decisions and advice generated by the model.
To address the need for standardization and clearer definitions in the HDT field, we propose a forward-looking roadmap organized into short- and long-term goals. In the short term, researchers should focus on adopting standardized terminology by promoting consistent use of the terms “digital twin” and “human digital twin” in alignment with NASEM criteria, and by clearly distinguishing related concepts such as general digital models, personalized digital models, digital shadows, and virtual patient cohorts. While comprehensive VVUQ may not be feasible in early-stage studies, researchers should aim to transparently report validation steps, modeling assumptions, and sources of uncertainty. Early interdisciplinary collaboration among academic, clinical, and industry stakeholders will also be critical to ensure that models are clinically relevant and grounded in real-world utility throughout their development. Finally, to improve reporting standards and methodological rigor, journals and funding bodies should encourage authors to provide clear descriptions of model architecture, data inputs, training and testing protocols, and performance evaluation metrics. Encouraging transparency in training data provenance and parameterization practices will further support reproducibility and facilitate meaningful comparison between models.
Over the longer term, more rigorous infrastructure and guidance will be needed to support scalable, trustworthy HDT deployment. This includes the development and adoption of HDT-specific VVUQ frameworks, potentially by adapting existing standards such as ASME V&V 40 to account for patient variability, real-time model updates, and clinical risk. Regulatory bodies such as the Food and Drug Administration and European Medicines Agency should be engaged to define approval pathways and evaluation criteria specific to HDTs. To support reproducibility and collaboration, shared infrastructure is also needed, including open-access data repositories, benchmark modeling tasks, and shared validation datasets. Finally, clinical implementation studies should be prioritized to evaluate how HDTs integrate into real-world workflows and influence decision-making, safety, and patient outcomes. By gradually integrating these actionable steps, a solid foundation is laid for the widespread implementation and efficacy of HDTs in healthcare.
link